

Are we overcomplicating alerting? And why does a system designed to notify us when things go wrong so often become part of the problem itself? These questions immediately came to mind when I saw Colin Douch’s Talk on the OSMC 2025 program. With experience as former Tech Lead of the Observability team at Cloudflare how is now at DuckDuckGo, he brought firsthand insight into the challenges of modern alert management.
Colin introduced Onotify, an alternative to Prometheus Alertmanager. As someone who has focused more on detecting failures than on managing alerts themselves, I was curious to see how a focus on usability, automation, and architecture choices could fundamentally reshape the alerting experience.
Introducing the Speaker and the Topic
At OSMC 2025, Colin Douch, former Tech lead of the Observability team at Cloudflare and current member of the Observability team at DuckDuckGo, presented his talk about a drop-in replacement for Prometheus Alertmanager called Onotify which has a focus on usability and scalability.
Alertmanager is weird
Missing authentication features is only the first difficulty with Alertmanager Colin presented. Creating a downtime just presents you with a text box where any name can be entered.
- Did you enter any name you just came up with?
- Did you enter it in the right format?
- Did you enter nothing at all?
All of these are totally fine in the eyes of Alertmanager. Which already seems like a bit of a step backward coming from older solutions like Icinga or Nagios.
A common solution for this issue is to use a custom Proxy which enriches the request, but there is no official support or middleware from Prometheus.

Alertmanager has no built-in automation features, no event handlers and once an event is resolved it is gone and to find more information about it the Prometheus upstream needs to be checked.
Alerts in Alertmanager don’t support histories or Acknowledgements. Acknowledgements in particular are hard to work with, since downstream Alert-Services typically implement this feature.
It is, however, not uncommon to have multiple alert service providers, each with their own Acknowledgement system. This, combined with the limited information problem above, leads to the issue where in order to get a full picture of the alert, you need to check Alertmanager, all the upstream Prometheus instances and all the downstream Alert Providers.
This setup is hardly a great user experience. And the current open-source nature of the project create a set of incentives, which leads to broad vendor support while simultaneously encouraging them to do as little as possible.
Identifying the Problem
What is the main issue that makes alert-management so hard?
Alerting is bursty: Alerts typically happen at the same time. Leading to a lot of resources that just sit around for most of the time, especially in a High Availability setup. And if things eventually go wrong, you still run the risk of overloading the alerting setup.
Cloudflare already has a great architecture pattern for exactly this purpose, The Serverless Architecture.
- Resources scale automatically as demand increases
- Durable objects allow for persistent replicated storage
- Authentication is built-in with Cloudflare Access
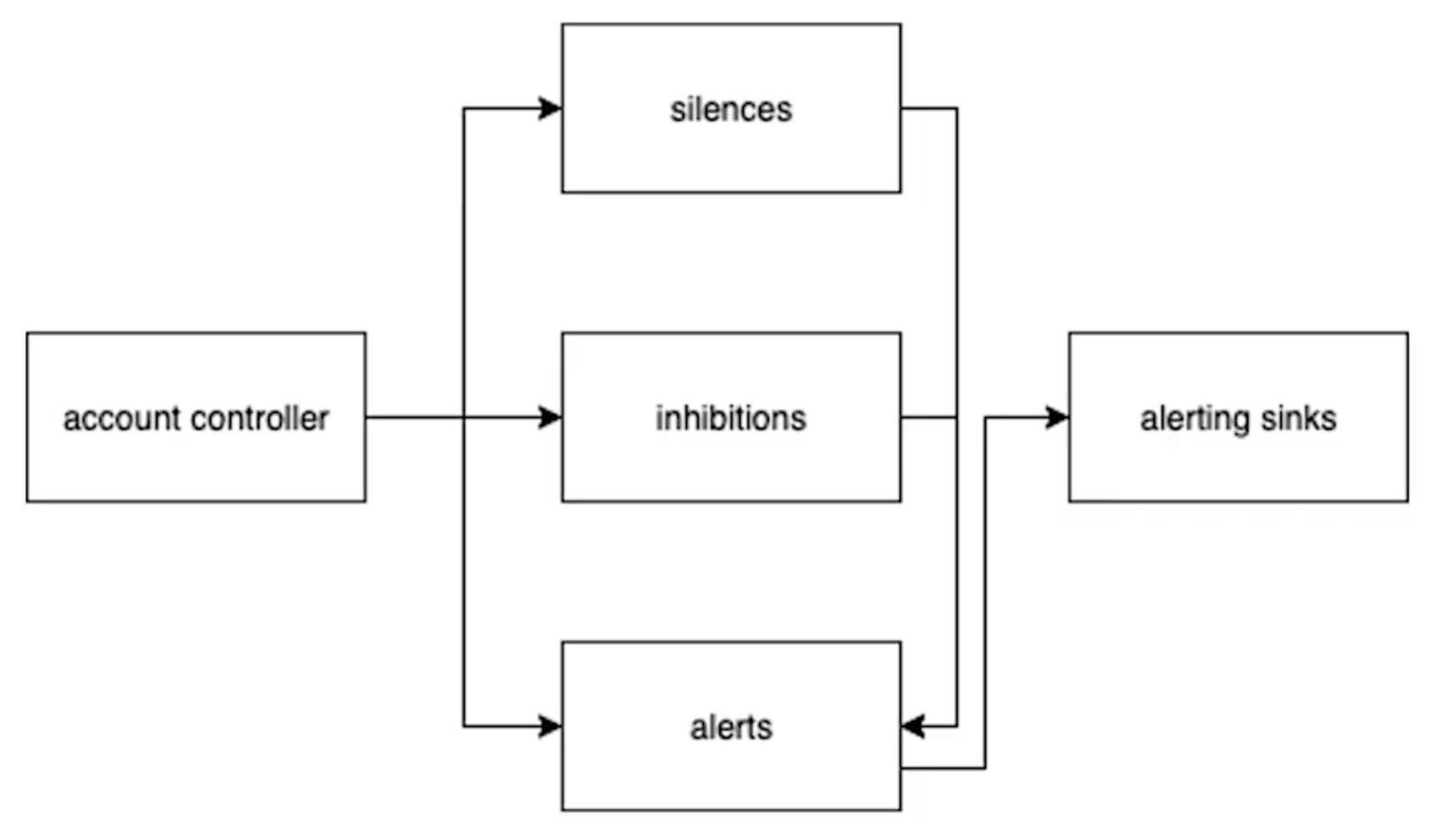
The Solution: Onotify
Next Colin presents a project that first saw its light at Cloudflare around 2019. A drop-in replacement for Alertmanager called Onotify.
Obviously, Onotify is deployed in the cloud as a Serverless application. It boasts a range of improvements over Alertmanager, such as faster evaluation of configuration thanks to Directed Acyclic Graphs, first-party support for user authentication, shareable links to specific alerts, pagination support for faster response times, a complete history of all events as well as native support for comments and acknowledgements.
Acknowledgements in particular are important since they synchronize with downstream alert providers. Making it possible to acknowledge an event in PagerDuty and have it reflected in Onotify.
My Personal Takeaways
What struck me the most is the complexity, in what seems like a relatively simple problem. For the longest time it was the detecting when something goes wrong that was the difficult part. Sending alerts people when something goes wrong seemed like a solved problem to me.
Another key takeaway of this talk was that **modern** systems might not always learn from the mistakes of the past, at least not at first. Sometimes you need to discover that old systems were built the way they are for a reason and that its more often than not, not a bad idea to look at the existing solutions.
I’m personally interested to see what will happen with Onotify and how the alert management space evolves and adapts.
Stay tuned for OSMC 2026
Save the date for the next OSMC taking place from November 17 – 19, 2026 in Nuremberg, Germany. This year, we will celebrate 20 years monitoring excellence. So make sure to be part of this special anniversary edition!




























0 Kommentare