Während man in Deutschland immer noch und immer wieder in Funklöchern sitzt und oftmals nur 2G als Datenübertragung nutzen kann, bereitet sich die Welt – auch Deutschland – auf den nächsten Standard vor: 5G. Die neue Generation besticht durch hohe Bandbreiten (~1-20Gbps), niedrige Latenzen und eine hohe mögliche Dichte von Geräten auf neuen Frequenzbändern, die natürlich heiß begehrt sind. Braucht man aber solch hohe Bandbreiten und niedrige Latenzen um seine E-Mails zu checken oder Social Media Inhalte zu betrachten? Wohl eher nicht. Diese neuen Anforderungen an das Netzwerk benötigen aber Anwendungen, die in Zukunft vermutlich nicht mehr wegzudenken sind und maßgeblich unsere Welt verändern könnten – so zumindest die Vision. Autonomes Fahren, künstliche Intelligenz, Augmented- und Virtual-Reality und Internet of Things sind nur einige Anwendungsbereiche, die durch den neuen Standard ihre Möglichkeiten besser ausschöpfen können.
Während man in Deutschland immer noch und immer wieder in Funklöchern sitzt und oftmals nur 2G als Datenübertragung nutzen kann, bereitet sich die Welt – auch Deutschland – auf den nächsten Standard vor: 5G. Die neue Generation besticht durch hohe Bandbreiten (~1-20Gbps), niedrige Latenzen und eine hohe mögliche Dichte von Geräten auf neuen Frequenzbändern, die natürlich heiß begehrt sind. Braucht man aber solch hohe Bandbreiten und niedrige Latenzen um seine E-Mails zu checken oder Social Media Inhalte zu betrachten? Wohl eher nicht. Diese neuen Anforderungen an das Netzwerk benötigen aber Anwendungen, die in Zukunft vermutlich nicht mehr wegzudenken sind und maßgeblich unsere Welt verändern könnten – so zumindest die Vision. Autonomes Fahren, künstliche Intelligenz, Augmented- und Virtual-Reality und Internet of Things sind nur einige Anwendungsbereiche, die durch den neuen Standard ihre Möglichkeiten besser ausschöpfen können.
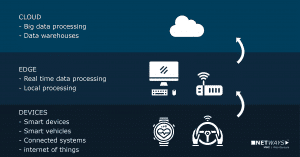
Ein völlig autonom fahrendes Auto, gespickt mit mehreren hundert Sensoren und vielen Kameras, produziert eine gewaltige Menge an Daten, die in einer Cloud zum Beispiel zur Koordination anderer Fahrzeuge eingespeist und verarbeitet werden. Ein weiteres Beispiel wäre die Videoüberwachung in einer U-Bahn kombiniert mit den Aufzeichnungen der Kameras vom Bahnsteig, die in Echtzeit menschliche Verhaltensmuster analysiert oder gar erlernt und entsprechend entscheidet. Benötigt es eine Vollbremsung, weil ein Passant gerade am Bahnsteig mit böser Absicht geschubst wird oder ist es eher eine harmlose Situation unter Freunden? Damit das funktioniert, benötigt man nicht nur ein schnelles Mobilfunknetz sondern auch Edge-Cloud-Computing.
Edge-Cloud-Computing
Edge-Cloud-Computing ist zu Recht einer der letzten und heißesten Trends im Bereich Cloud-Computing. Dabei gilt es, seine zentrale Cloud an den Rand (Edge) zu bewegen – also näher an den Kunden. Mit anderen Worten eine verteilte Cloud. Was genau jetzt der Rand sein soll ist noch nicht so ganz klar, man nimmt einen Bereich an, der nicht weiter als 20ms vom Endgerät entfernt ist. An diesem Rand ist es also nun notwendig, seine Cloud-Compute-Ressourcen verfügbar zu haben und nutzen zu können, um entsprechende Workload darauf zu betreiben. Ob die Workload in Containern, VMs oder Bare-Metal betrieben wird ist eher nachrangig zu betrachten, der Mix wird es sein. Dabei stützt man sich auf bestehende Technologie-Komponenten wie etwa Ceph, Qemu, Kubernetes, DPDK, OpenVSwitch und so weiter. 5G alleine wird also ohne Edge-Computing vermutlich nicht reichen, um zukünftigen Anwendungen gerecht zu werden.
Die beiden Open-Source Cloud-Lösungen, OpenNebula und OpenStack, die wir auch bei NETWAYS im Einsatz haben, sind natürlich bereits auf den Hype-Train aufgesprungen. OpenNebula hat gleich ihr gestriges Release 5.8 dem Codenamen „Edge“ verpasst und OpenStack hat mit StarlingX sein eigenes Projekt und ein „Edge Computing Group“ Gremium ins Leben gerufen.
Man kann wirklich gespannt sein was die Zukunft bringen wird und wie die Herausforderungen technisch realisiert werden.
Anwendungen, die ohne 5G und Edge auskommen, können aber auch schon heute in unserer Cloud basierend auf OpenStack modern, zeitgemäß und zukunftssicher betrieben werden.

 Seit bereits sieben Jahren betreiben wir bei NETWAYS eine
Seit bereits sieben Jahren betreiben wir bei NETWAYS eine