This entry is part 65 of 63 in the series NETWAYS stellt sich vor
NETWAYS Blog
Hier erfährst Du alles was uns bewegt. Technology, Hardware, das Leben bei NETWAYS, Events, Schulungen und vieles mehr.

Vielseitige Einblicke der Abteilungswoche bei NETWAYS
In der modernen Arbeitswelt ist es wichtig, über den eigenen Tellerrand hinauszuschauen und ein Verständnis für verschiedene Bereiche eines Unternehmens zu entwickeln. Genau aus diesem Grund wurde bei NETWAYS die Idee der Abteilungswoche geboren. In dieser Woche hatte...

OSCamp für Kubernetes 2024 – Rückblick auf ein inspirierendes Event
Das gestrige Open Source Camp für Kubernetes war ein Riesenerfolg! Von inspirierenden Keynotes bis hin zu lebhaften Diskussionen bot das Event eine Fülle an Wissen und Networking-Möglichkeiten. Highlights aus dem Programm Die Talks lieferten nicht nur Blicke...

Spoiler Alert – The stackconf 2024 Program is Set!
The wait is over! We’re pleased and excited to finally announce the agenda for this year’s stackconf. The event focused on cloud native & infrastructure solutions takes place from June 18 – 19 in Berlin, Germany. Highlights from the Schedule Here's a...
Lösungen & Technology
Kritisch: Fehler in Elasticsearch mit JDK22 kann einen sofortigen Stop des Dienstes bewirken
Update Seit gestern Abend steht das Release 8.13.2 mit dem BugFix zur Verfügung. Kritischer Fehler Der Elasticsearch Dienst kann ohne Vorankündigung stoppen. Diese liegt an einem Fehler mit JDK 22. In der Regel setzt man Elasticsearch mit der "Bundled" Version ein....
Kritisch: Fehler in Elasticsearch mit JDK22 kann einen sofortigen Stop des Dienstes bewirken
Update Seit gestern Abend steht das Release 8.13.2 mit dem BugFix zur Verfügung. Kritischer Fehler Der Elasticsearch Dienst kann ohne Vorankündigung stoppen. Diese liegt an einem Fehler mit JDK 22. In der Regel setzt man Elasticsearch mit der "Bundled" Version ein....

Kritisch: Fehler in Elasticsearch mit JDK22 kann einen sofortigen Stop des Dienstes bewirken
Update Seit gestern Abend steht das Release 8.13.2 mit dem BugFix zur Verfügung. Kritischer Fehler Der Elasticsearch Dienst kann ohne Vorankündigung stoppen. Diese liegt an einem Fehler mit JDK 22. In der Regel setzt man Elasticsearch mit der "Bundled" Version ein....

NETWAYS GitHub Update März 2024

End of Life von CentOS Linux 7 – Was bedeutet das für mich?
Der ein oder andere Admin wird sich vermutlich schon lange den 30. Juni 2024 im Kalender vorgemerkt haben, denn dann ist für CentOS Linux 7 das "End of Life" erreicht. Aber auch Benutzer von Red Hat Enterprise Linux 7 sollten sich Gedanken machen, denn auch dieses...
NETWAYS GitHub Update Februar 2024
Events & Trainings
Spoiler Alert – The stackconf 2024 Program is Set!
The wait is over! We’re pleased and excited to finally announce the agenda for this year’s stackconf. The event focused on cloud native & infrastructure solutions takes place from June 18 – 19 in Berlin, Germany. Highlights from the Schedule Here's a...
Spoiler Alert – The stackconf 2024 Program is Set!
The wait is over! We’re pleased and excited to finally announce the agenda for this year’s stackconf. The event focused on cloud native & infrastructure solutions takes place from June 18 – 19 in Berlin, Germany. Highlights from the Schedule Here's a...
Spoiler Alert – The stackconf 2024 Program is Set!
The wait is over! We’re pleased and excited to finally announce the agenda for this year’s stackconf. The event focused on cloud native & infrastructure solutions takes place from June 18 – 19 in Berlin, Germany. Highlights from the Schedule Here's a...

OSMC 2023 | Experiments with OpenSearch and AI
Last year's Open Source Monitoring Conference (OSMC) was a great experience. It was a pleasure to meet attendees from around the world and participate in interesting talks about the current and future state of the monitoring field. Personally, this was my first time...

OSCamp 2024 | Großen Dank an unsere Sponsoren!
Wir sagen Dankeschön! Die Vorbereitungen für das OSCamp für Kubernetes 2024 sind in vollem Gange, und während wir uns auf das kommende Event freuen, möchten wir die Gelegenheit nutzen, um unseren Gold-Sponsoren zu danken. Ihre großzügige Unterstützung macht diese...

OSMC 2024 is Calling for Sponsors
What about positioning your brand in a focused environment of international IT monitoring professionals? Discover why OSMC is just the perfect spot for it. Meet your Target Audience Sponsoring the Open Source Monitoring Conference is a fantastic opportunity to...
Web Services
CfgMgmtCamp 2024: Unser Rückblick
Vergangene Woche fuhr ein Teil unseres Teams bei NWS bis nach Ghent in Belgien, um am ConfigManagementCamp 2024 teilzunehmen. Hierbei handelt es sich um eine kostenlose Konferenz, direkt im Anschluss an die FOSDEM, was Jahr für Jahr für ein großes Publikum aus Fans...
CfgMgmtCamp 2024: Unser Rückblick
Vergangene Woche fuhr ein Teil unseres Teams bei NWS bis nach Ghent in Belgien, um am ConfigManagementCamp 2024 teilzunehmen. Hierbei handelt es sich um eine kostenlose Konferenz, direkt im Anschluss an die FOSDEM, was Jahr für Jahr für ein großes Publikum aus Fans...

CfgMgmtCamp 2024: Unser Rückblick
Vergangene Woche fuhr ein Teil unseres Teams bei NWS bis nach Ghent in Belgien, um am ConfigManagementCamp 2024 teilzunehmen. Hierbei handelt es sich um eine kostenlose Konferenz, direkt im Anschluss an die FOSDEM, was Jahr für Jahr für ein großes Publikum aus Fans...

Effektive Zugriffskontrolle für GitLab Pages
Grundlagen von GitLab Pages GitLab Pages sind eine facettenreiche Funktion, die es ermöglicht, statische Webseiten direkt aus einem GitLab-Repository heraus zu hosten. Diese Funktionalität eröffnet eine breite Palette von Anwendungsmöglichkeiten, von der Erstellung...

Ceph Backfilling Crash: Datenintegrität manuell wiederherstellen
Seit vielen Jahren haben wir Ceph im Einsatz. Unser erstes produktives Cluster begleitet uns seit 2015. Auch wenn die ersten Major-Updates des Clusters holprig verliefen ist die nötige Pflege des Clusters mit jedem Release von Ceph geringer geworden. Abgesehen vom...

Why We’re Excited About DevOps Camp 2023!
This year, our NETWAYS Web Services Team is highly motivated to participate in DevOps Camp in Nuremberg! After a short break since stackconf in Berlin, we are back at a conference. We are delighted to be able to support DevOps Camp once again. In this article, we...
Unternehmen
Vielseitige Einblicke der Abteilungswoche bei NETWAYS
In der modernen Arbeitswelt ist es wichtig, über den eigenen Tellerrand hinauszuschauen und ein Verständnis für verschiedene Bereiche eines Unternehmens zu entwickeln. Genau aus diesem Grund wurde bei NETWAYS die Idee der Abteilungswoche geboren. In dieser Woche hatte...
OSCamp für Kubernetes 2024 – Rückblick auf ein inspirierendes Event
Das gestrige Open Source Camp für Kubernetes war ein Riesenerfolg! Von inspirierenden Keynotes bis hin zu lebhaften Diskussionen bot das Event eine Fülle an Wissen und Networking-Möglichkeiten. Highlights aus dem Programm Die Talks lieferten nicht nur Blicke...

Monthly Snap März 2024
Endlich Frühling in Nürnberg! Die Laune ist doch morgens gleich besser, wenn es schon hell ist, wenn man aus dem Haus geht. Wir haben im März viele schöne Blogposts für Euch gehabt. Falls Ihr welche davon verpasst hat, hier ein Überblick für Euch. Aber natürlich...
Blogroll
Da hast Du einiges zu lesen …

NETWAYS stellt sich vor – Abhishekh Reghunath
 Name: Abhishekh Reghunath
Name: Abhishekh Reghunath
Abhishekh Reghu Nath
Junior Consultant
Nach seinem Umzug nach Deutschland im Jahr 2022 begann Abhishekh sein Bachelorstudium in International Business. Nach einigen Semestern entschied er sich für die Ausbildung zum Fachinformatiker für Daten und Prozessanalyse und startete im September 2023 bei NETWAYS Professional Services. In seiner Freizeit geht er gerne ins Fitnesscenter oder kocht.
Vielseitige Einblicke der Abteilungswoche bei NETWAYS
In der modernen Arbeitswelt ist es wichtig, über den eigenen Tellerrand hinauszuschauen und ein Verständnis für verschiedene Bereiche eines Unternehmens zu entwickeln. Genau aus diesem Grund wurde bei NETWAYS die Idee der Abteilungswoche geboren. In dieser Woche hatte ich das Privileg, einen tiefen Einblick in verschiedene Abteilungen zu bekommen und deren tägliche Aufgaben kennenzulernen.
Tag 1: Marketing
Der Start meiner Abteilungswoche führte mich direkt in die Marketingabteilung. Hier habe ich einen Überblick über die laufenden Kampagnen, Strategien und Analysen bekommen. Ich durfte an einer Brainstorming-Sitzungen teilnehmen und neue Ideen einbringen. Es war faszinierend zu sehen, wie kreativ und strategisch das Marketingteam arbeitet, um die Marke von NETWAYS zu stärken.
Tag 2: Finance & Administration
Am zweiten Tag tauchte ich in die Welt der Finanzen und Verwaltung ein. Hier erhielt ich einen Einblick in die Buchhaltung, Budgetplanung und Verwaltungsaufgaben. Obwohl Zahlen normalerweise nicht meine Stärke sind, konnte ich durch die Unterstützung meines Teams grundlegende Finanzkonzepte verstehen und sogar Mahnungen und Buchungen selbständig erstellen. Diese Erfahrung half mir, die Bedeutung einer effizienten Verwaltung für den reibungslosen Ablauf eines Unternehmens zu erkennen.
Tag 3: Events & Services
Am dritten Tag erhielt ich Einblicke vom Team NETWAYS Event Services. Hier lernte ich, wie Veranstaltungen von NETWAYS geplant, organisiert und durchgeführt werden. Von der Auswahl der Location über die Koordination von Lieferanten bis hin zur Betreuung der Gäste – das Events-Team leistet eine beeindruckende Arbeit, um sicherzustellen, dass jede Veranstaltung ein voller Erfolg wird.
Tag 4: Sales
Meine Abteilungswoche endete mit einem Einblick in die Vertriebsabteilung. Hier lernte ich, wie Produkte oder Dienstleistungen an Kunden verkauft werden und wie wichtig es ist, starke Kundenbeziehungen aufzubauen. Ich begleitete das Vertriebsteam und lernte Verkaufsstrategien kennen und durfte sogar bei der Erstellung von Angeboten unterstützen. Es war beeindruckend zu sehen, wie das Sales-Team mit Leidenschaft und Überzeugungskraft arbeitet, um die Umsatzziele von NETWAYS zu erreichen.
Fazit: Eine bereichernde Erfahrung
Die Abteilungswoche war eine unvergessliche Erfahrung, die mir nicht nur einen umfassenden Einblick in die verschiedenen Bereiche des Unternehmens verschafft hat, sondern auch meine beruflichen Fähigkeiten und mein Verständnis für die Zusammenarbeit zwischen verschiedenen Abteilungen erweitert hat. Ich bin dankbar für diese Gelegenheit und freue mich darauf vielleicht sogar das Gelernte in meiner eigenen Arbeit anzuwenden.

Gökhan Peker
Junior Consultant
Gökhan ist seit September 2023 bei NETWAYS und macht seine Ausbildung zum Fachinformatiker für Systemintegration. Mit der Ausbildung geht er seiner Leidenschaft nach und unterstützt das Professionelle Services Team. Seine Freizeit verbringt er gerne mit Freunden, mal draußen oder mal an einem Gaming Abend. Auch hört er gerne Musik, vor allem beim Training. Und wenn mal Zeit übrig ist werden Videos editiert
OSCamp für Kubernetes 2024 – Rückblick auf ein inspirierendes Event
Das gestrige Open Source Camp für Kubernetes war ein Riesenerfolg! Von inspirierenden Keynotes bis hin zu lebhaften Diskussionen bot das Event eine Fülle an Wissen und Networking-Möglichkeiten.
Highlights aus dem Programm
Die Talks lieferten nicht nur Blicke auf die gegenwärtigen Herausforderungen und Chancen, sondern wagten auch einen Ausblick auf die Zukunft der Container-Orchestrierung.

Magnus Kulke eröffnete das Programm mit seinem Vortrag über die grundlegenden Konzepte des Confidential Computing. Anschließend sprachen Andreas Hahn und Leon Müller von der Nürnberger Versicherung ganz offen über die Herausforderungen und Chancen der Cloud-Transformation bei Nicht-IT Unternehmen. Achim Ledermüller von NETWAYS Web Services zeigte, wie #OIDC mit #Kubernetes konfiguriert und genutzt werden kann und welche Vorteile der neue Resource Typ AuthenticationConfiguration mit sich bringt.

Besonders in Erinnerung bleiben wird uns der interessante und amüsante Vortrag von Jochen Metzger über Kubernetes und KI-Tools. Auch Alex Pshe lieferte tolle Einblicke und präsentierte einen Schritt-für-Schritt-Algorithmus, der dabei unterstützt, ein automatisiertes Qualitätskontrollsystem für den Aufbau von CI/CD zu entwickeln.
 Nach der Mittagspause ging es direkt weiter mit Patrick Münch, der die Frage „Warum IT-Sicherheit innovativ sein muss“ beantwortete. Isabelle Rotter folgte mit einem nicht-technischen, aber sehr inspirierenden Vortrag darüber, wie man mit neuen Ansätzen die Kommunikation in Teams verbessern kann. Desweiteren sprachen Eric Lippmann über „Monitoring von Kubernetes mit Icinga“, Thilo Fromm über „Zero-Touch OS-Infrastruktur für Container und Kubernetes-Workloads“ und Alex König über „Running Web Assembly in Kubernetes“. Abgeschlossen haben den gestrigen Tag Andreia Otto und Ravikanth Mogulla von Adidas, indem sie SRE-Herausforderungen bei der Umstellung von Monolithen auf Microservices bei adidas E-commerce beleuchteten.
Nach der Mittagspause ging es direkt weiter mit Patrick Münch, der die Frage „Warum IT-Sicherheit innovativ sein muss“ beantwortete. Isabelle Rotter folgte mit einem nicht-technischen, aber sehr inspirierenden Vortrag darüber, wie man mit neuen Ansätzen die Kommunikation in Teams verbessern kann. Desweiteren sprachen Eric Lippmann über „Monitoring von Kubernetes mit Icinga“, Thilo Fromm über „Zero-Touch OS-Infrastruktur für Container und Kubernetes-Workloads“ und Alex König über „Running Web Assembly in Kubernetes“. Abgeschlossen haben den gestrigen Tag Andreia Otto und Ravikanth Mogulla von Adidas, indem sie SRE-Herausforderungen bei der Umstellung von Monolithen auf Microservices bei adidas E-commerce beleuchteten.











Danke an die Sponsoren!
An dieser Stelle möchten wir unseren Sponsoren Icinga, Tigera und NETWAYS Web Services für deren großartige Unterstützung danken. Es war uns eine Ehre, Euch beim OSCamp 2024 mit dabei zu haben!
![]()


Insgesamt war das OSCamp für Kubernetes 2024 eine großartige Erfahrung, die die Teilnehmer mit neuer Motivation und frischen Perspektiven nach Hause gehen ließ. Wir freuen uns schon auf das OSCamp im nächsten Jahr – bleibt gespannt!

Katja Kotschenreuther
Manager Marketing
Katja ist seit Oktober 2020 Teil des Marketing Teams. Als Manager Marketing kümmert sie sich hauptsächlich um das Marketing für die Konferenzen stackconf und OSMC sowie unsere Trainings. Zudem unterstützt sie das Icinga Team mit verschiedenen Social Media Kampagnen und der Bewerbung der Icinga Camps. Sie ist SEO-Verantwortliche für all unsere Websites und sehr viel in unserem Blog unterwegs. In ihrer Freizeit reist sie gerne, bastelt, backt und engagiert sich bei Foodsharing. Im Sommer kümmert sie sich außerdem um ihren viel zu großen Gemüseanbau.
Spoiler Alert – The stackconf 2024 Program is Set!
The wait is over! We’re pleased and excited to finally announce the agenda for this year’s stackconf. The event focused on cloud native & infrastructure solutions takes place from June 18 – 19 in Berlin, Germany.
Highlights from the Schedule
Here’s a glimpse into a few of our keynote speakers, but there are plenty more on our website. Be sure to have a look and bookmark your favourites!
 BILL MULLIGAN, Isovalent
BILL MULLIGAN, Isovalent
 BILL MULLIGAN, Isovalent
BILL MULLIGAN, IsovalentBuzzing Across The eBPF Landscape And Into The Hive
Bill’s talk on the rising eBPF technology buzz covers its applications and guidance for beginners and experts. He shares his journey into eBPF, its benefits like efficient networking and real-time security, and highlights various applications. Attendees learn about the eBPF landscape, new tools, and how eBPF addresses networking, observability, and security challenges.

ANAÏS URLICHS, Aqua Security
Looking into the Closet from Code to Cloud with Bills of Material
Anaïs‘ talk covers various Bills of Material (BOM) types, generated from Code to Cloud resources using tools like Trivy, Syft, and Microsoft SBOM. Attendees compare BOM outputs for security and quality using sbom-comparator by Lockheed Martin, with a live demo showcasing their benefits for security scans and reducing vulnerability scan noise.

ALEX PSHE, JetBrains
Step-by-step algorithm for building CI/CD as an automated quality control system
In Alex’s talk, delve into the tester’s CI/CD perspective, leveraging automatic metric control for decisions. Learn about constructing CI/CD pipelines based on test metrics, the fail-first approach, and utilizing various pipeline types for testing. Key criteria for effective pipelines, including quality gates and automated control systems, are emphasized.

MAGNUS KULKE, Microsoft
Confidential Containers – Sensitive Data and Privacy in Cloud Native Environments
Magnus‘ talk introduces Confidential Container technology for processing sensitive data in cloud-native environments. He discusses its implementation in Linux and hardware and evaluates the progress of the „Confidential Containers“ project. Finally, a practical demonstration of confidential container deployment in Kubernetes is showcased.

ALAYSHIA KNIGHTEN, Pulumi
Unleashing Potential Across Teams: The Power of Infrastructure as Code
Alayshia’s talk showcases how Infrastructure as Code (IaC) revolutionizes managing diverse infrastructures, offering ease and agility. Attendees learn practical strategies for implementation, fostering collaboration and boosting productivity across technical backgrounds.
Save your Ticket!
Don’t miss out on grabbing one of our available tickets before they’re gone! If you have any friends or colleagues who might be interested too, come together and benefit from our team discount. We’re looking forward to meeting you!
Katja Kotschenreuther
Manager Marketing
Katja ist seit Oktober 2020 Teil des Marketing Teams. Als Manager Marketing kümmert sie sich hauptsächlich um das Marketing für die Konferenzen stackconf und OSMC sowie unsere Trainings. Zudem unterstützt sie das Icinga Team mit verschiedenen Social Media Kampagnen und der Bewerbung der Icinga Camps. Sie ist SEO-Verantwortliche für all unsere Websites und sehr viel in unserem Blog unterwegs. In ihrer Freizeit reist sie gerne, bastelt, backt und engagiert sich bei Foodsharing. Im Sommer kümmert sie sich außerdem um ihren viel zu großen Gemüseanbau.
OSMC 2023 | Experiments with OpenSearch and AI
Last year’s Open Source Monitoring Conference (OSMC) was a great experience. It was a pleasure to meet attendees from around the world and participate in interesting talks about the current and future state of the monitoring field.
Personally, this was my first time attending OSMC, and I was impressed by the organization, the diverse range of talks covering various aspects of monitoring, and the number of attendees that made this year’s event so special.
If you were unable to attend the congress, we are being covering some of the talks presented by the numerous specialists.
This blog post is dedicated to this year’s Gold Sponsor Eliatra and their wonderful speakers Leanne Lacey-Byrne and Jochen Kressin.
Could we enhance accessibility to technology by utilising large language models?
This question may arise when considering the implementation of artificial intelligence in a search engine such as OpenSearch, which handles large data structures and a complex operational middleware.
This idea can also be seen as the starting point for Eliatra’s experiments and their findings, which is the focus of this talk.
Working with OpenSearch Queries
OpenSearch deals with large amounts of data, so it is important to retrieve data efficiently and reproducibly.
To meet this need, OpenSearch provides a DSL which enables users to create advanced filters to define how data is retrieved.
In the global scheme of things, such queries can become very long and therefore increase the complexity of working with them.
What if there would be a way of generating such queries by just providing the data scheme to a LLM (large language model) and populate it with a precise description of what data to query? This would greatly reduce the amount of human workload and would definitely be less time-consuming.
Can ChatGPT be the Solution?
As a proof-of-concept, Leanne decided to test ChatGPT’s effectiveness in real-world scenarios, using ChatGPT’s LLM and Elasticsearch instead of OpenSearch because more information was available on the former during ChatGPT’s training.
The data used for the tests were the Kibana sample data sets.
Leanne’s approach was to give the LLM a general data mapping, similar to the one returned by the API provided by Elasticsearch, and then ask it a humanised question about which data it should return. Keeping that in mind, this proof of concept will be considered a success if the answers returned consist of valid search queries with a low failure rate.
Performance Analysis
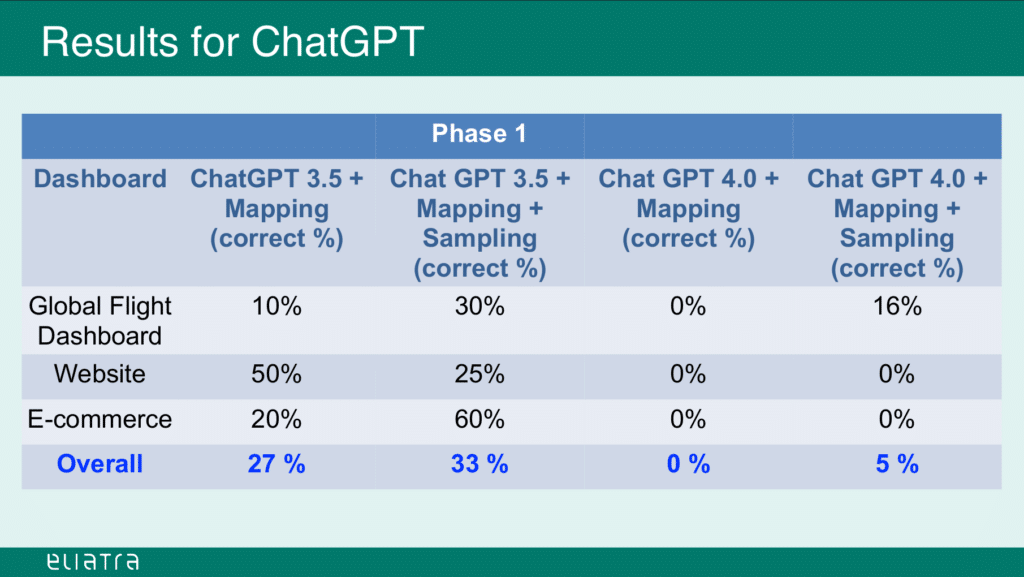
Source: slideshare.net (slide 14)
As we can see, the generated queries achieved only 33% overall correctness. And this level was only possible by feeding the LLM with a number of sample mappings and the queries that were manually generated for them.
Now, this accuracy could be further improved by providing more information about the mapping structures, and by submitting a large number of sample mappings and queries to the ChatGPT instance.
This would however result in much more effort in terms of compiling and providing the sample datasets, and would still have a high chance of failure for any submitted prompts that deviate from the trained sample data.
Vector Search: An Abstract Approach
Is there a better solution to this problem? Jochen presents another approach that falls under the category of semantic search.
Large language models can handle various inputs, and the type of input used can significantly impact the results produced by such a model.
With this in mind, we can transform our input information into vectors using transformers.
The transformers are trained LLM models that process specific types of input, for example video, audio, text, and so on.
They generate n-dimensional vectors that can be stored in a vector database.
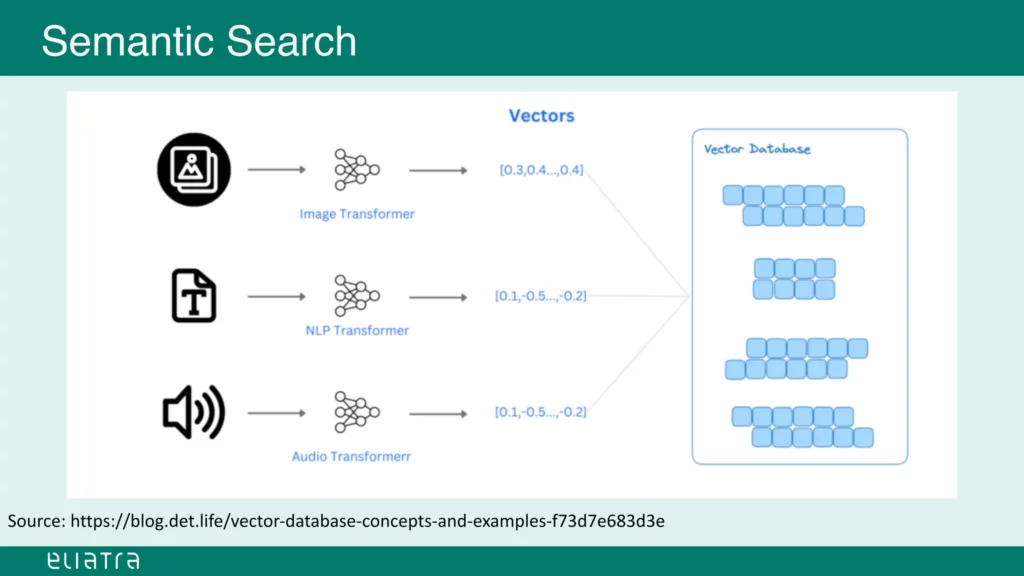
Source: slideshare.net (slide 20)
When searching a vector-based database, one frequently used algorithm for generating result sets is the ‚K-NN index‘
(k-nearest-neighbour index). This algorithm compares stored vectors for similarity and provides an approximation of their relevance to other vectors.
For instance, pictures of cats can be transformed into a vector database. The transformer translates the input into a numeric, vectorized format.
The vector database compares the transformed input to the stored vectors using the K-NN algorithm and returns the most fitting vectors for the input.
Are Vectors the Jack of all Trades?
There are some drawbacks to the aforementioned approach. Firstly, the quality of the output heavily depends on the suitability between the transformer and the inputs provided.
Additionally, this method requires significantly more processing power to perform these tasks, which in a dense and highly populated environment could be the bottleneck of such an approach.
It is also difficult to optimize and refine existing models when they only output abstract vectors and are represented as black boxes.
What if we could combine the benefits of both approaches, using lexical and vectorized search?
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) was first mentioned in a 2020 paper by Meta. The paper explains how LLMs can be combined with external data sources to improve search results.
This overcomes the problem of stagnating/freezing models, in contrast to normal LLM approaches. Typically, models get pre-trained with a specific set of data.
However, the information provided by this training data can quickly become obsolete and there may be a need to use a model that also incorporates current developments, the latest technology and currently available information.
Augmented generation involves executing a prompt against an information database, which can be of any type (such as the vector database used in the examples above).
The result set is combined with contextual information, for example the latest data available on the Internet or some other external source, like a flight plan database.
This combined set could then be used as a prompt for another large language model, which would produce the final result against the initial prompt.
In conclusion, multiple LLMs could be joined together while using their own strengths and giving them access to current data sources and that could in turn generate more accurate and up to date answers for user prompts.
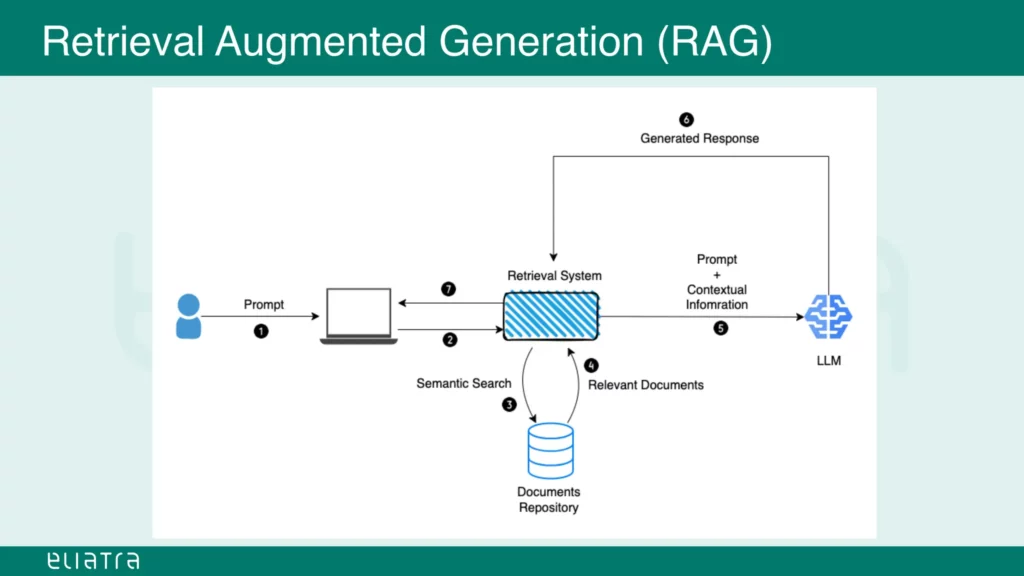
Source: slideshare.net (slide 36)

Noé Costa
Developer
Noé ist als Schweizer nach Deutschland ausgewandert und unterstützt das Icinga Team seit Oktober 2023 als Developer im Bereich der Webentwicklung. Er wirkt an der Weiterentwicklung der Webmodule von Icinga mit und ist sehr interessiert am Bereich des Monitorings und dessen Zukunft. Neben der Arbeit kocht er gerne, verbringt Zeit mit seiner Partnerin, erweitert sein Wissen in diversen Gebieten und spielt ab und an auch Computerspiele mit Bekanntschaften aus aller Welt.
















